期刊信息
曾用名:现代图书情报技术;计算机与图书馆
主办:中国科学院文献情报中心
主管:中国科学院
ISSN:2096-3467
CN:10-1478/G2
语言:中文
周期:月刊
影响因子:0.912234
数据库收录:
北大核心期刊(2004版);北大核心期刊(2008版);北大核心期刊(2011版);北大核心期刊(2017版);中国科学引文数据库(2017-2018);中国科学引文数据库(2019-2020);中文社会科学引文索引-来源(2017-2018);中文社会科学引文索引-来源(2019-2020);国家哲学社会科学学术期刊数据库;中国人文社科核心期刊;中国科技核心期刊;期刊分类:图书情报与数字图书馆
期刊热词:
研究论文
知识图谱的想象力有多丰富?
【作者】网站采编
【关键词】
【摘要】当你看到这张照片,你能得到什么信息? ? ? 这是一张来自很久前的黑白照片,照片中的人是一个外国人。 那么他是谁呢? 通过观察图片,你会发现这个人的名字是Thierry Hermès。 这时
当你看到这张照片,你能得到什么信息?
 ? ?
? ?
这是一张来自很久前的黑白照片,照片中的人是一个外国人。
那么他是谁呢?
通过观察图片,你会发现这个人的名字是Thierry Hermès。
这时也许你会马上联想到Hermès、爱马仕....
经过进一步检索,你发现Thierry Hermès是爱马仕的创始人;1837年他在法国巴黎创立了爱马仕,早年以制造高级马具起家。
上述例子中的思考过程,正是机器学习的目标:让机器学会像人类一样思考、判断、链接信息。
人工智能分为三个阶段,从机器智能到感知智能,再到认知智能。认知智能的目标是让机器拥有像人类一样的思考能力,但现实却是AI要达到一个两、三岁小孩的智力都很难,这背后很大一部分原因是机器缺少知识,缺少将不同的信息点串联起来形成对事物的整体认知和判断的能力。
近几年,人工智能已经有了突飞猛进的进展,引入人类的知识是AI的重要研究方向之一,知识图谱的构建,将所有不同种类的信息(Heterogeneous Information)连接在一起,旨在为智能系统表征知识,从而获得解决复杂问题的能力。
1
知识图谱
在过去的几年里,数说故事陆续根据实际客户需求,构建固定领域、固定知识结构的知识图谱,服务于信息查询,垂直领域智能问答,产品创新等不同应用。
在过往的服务中,这种“固定”知识图谱可以达到相对较高的准确性,但是对于使用有较大的限制。只能在预先定义的结构中进行探索查询,无法将更多的知识容纳进来,导致任何的知识结构改变都需要重训练新的模型,改造代价非常大。
如何在一个更加通用的框架实现客户需求和技术的统一,是数说故事一直努力的方向。
历经数次迭代,数说故事使用知识图谱的技术构建了一个通用型商业知识图谱,区别于传统的开放性知识图谱,如Freebase、YAGO、DBpedia等,我们构建的知识图谱在开放性知识图谱的前提下,主要面向商业研究领域丰富知识链接,以“品牌 - 产品 - 人 - 媒介”为核心向外不断拓展。
目前,该图谱依托数说故事XDP体系,实现近实时数据解析入库,包含100w+实体,近亿级实体关系。
数说故事 Mamba Search是一个基于通用型商业知识图谱的开放性实体属性挖掘系统。基于数说聚合全量数据解析生成,实现全场景知识体系覆盖。Mamba Search“探索、关联、拓展”三大功能,让原本无法具象展示的知识图谱变得触手可得。
下文将围绕数说故事在开放性知识提取和实体推断上使用的技术手段及以下两大难点展开介绍。
开发型知识图谱的算法复杂度较高,如何做到无指定对象的开放性三元组抽取?
开放型知识图谱提取结果没有经过有效的归类,下游业务难以使用,怎么办?
2
知识抽取
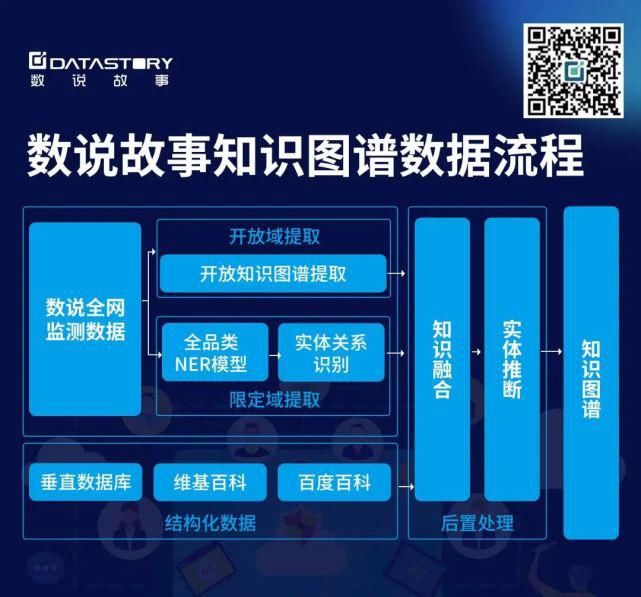 上图是我们现有的知识图谱数据流程,核心算法在于开放域抽取以及限定域抽取两个部分。基于自然语言处理抽取的知识分成两种明确不同的类别:开放语义的主谓宾关系,以及限定关系类型的基于长依赖的实体关系抽取。
上图是我们现有的知识图谱数据流程,核心算法在于开放域抽取以及限定域抽取两个部分。基于自然语言处理抽取的知识分成两种明确不同的类别:开放语义的主谓宾关系,以及限定关系类型的基于长依赖的实体关系抽取。
2.1 开放域抽取
开放域抽取,基于语义的主谓宾关系,如:“杨幂代言雅诗兰黛”,我们可以抽取出“[杨幂] - [代言] - [雅诗兰黛]”这样的三元组关系。
开放性知识提取,即从文章中提取由主语、谓语和宾语组成的知识,这是构建知识图谱的核心步骤;开放性指的是不限定谓语的类型,理论上可提取出无限种主语和宾语之间的关系。
为了适应社交媒体和不同数据源复杂的语言环境,不同于一般的从原文中直接提取三元组(主语、谓语和宾语)的方案,数说故事知识图谱采取了NER+关系二元组的知识提取方案,我们自研了MELSE模型结构(multi entity-oriented labeling stage extraction model),这样比直接提取三元组结构的传统方案能够提升大概7%的召回率。具体可以分为以下步骤:

 将要分析的实体作为“下一句”拼接在原文后,输入数说定制的BERT模型层,将输出的embedding分别输入三个不同的线性转换层,分别得到原文的关系二元组,当原文中的关系二元组多于一个时,可通过对应关系标签,获取谓语和宾语之间的对应关系。
将要分析的实体作为“下一句”拼接在原文后,输入数说定制的BERT模型层,将输出的embedding分别输入三个不同的线性转换层,分别得到原文的关系二元组,当原文中的关系二元组多于一个时,可通过对应关系标签,获取谓语和宾语之间的对应关系。
2.2 限定域抽取
限定域抽取,基于依赖推理的关系抽取:如:“元气森林推出的气泡水,味道清新,不腻,有利于减肥”,我们需要从中抽取多个关系对。数说定义了商业知识图谱相关的50+特殊关系类型,从品牌研究,到产品研发,再到人群分析,我们都设计了特殊的实体关系类型。
文章来源:《数据分析与知识发现》 网址: http://www.sjfxyzsfx.cn/zonghexinwen/2020/1008/333.html